baier-ru.ru - Байер посредник в Китае (Taobao, 1688, Poizon). Работаю напрямую — без переплат. Доставка в РФ под ключ!
21
В сети1.5k
Пользователи2.0k
Темы3.0k
Сообщения-
Байер посредник пойзон под ключ
-
Производство бетонных столбов Ессентуки с доставкой по РФ
Надежное и долговечное решение для создания ограждений и других конструкций на садовых и огородных участках. Закажите бетонные столбы у нас и получите качественный продукт по выгодной цене! antarius26.ru/pillars
-
Купить станок буратино для восстановления резьбы
У нас вы можете купить расточно наплавочный комплекс, станок для ремонта оси грузового автомобиля по доступной цене. Это даст возможность производить восстановительные работы по ремонту самостоятельно без демонтажа изношенной оси. ООО “Пульсар” является автором и разработчиком единственного в России и уникального станка БУРАТИНА: buratina72.ru
-
Производство сэндвич панелей
panel.shenox.ru - Завод ШЕНОКС занимается производством и продажей кровельных и стеновых сэндвич панелей в Москве и регионах России. Производство сэндвич панелей из минеральной ваты, пенополиуретана (ППУ), пенополистирола (ППС), пенополиизоцианурата, сэндвич панели PIR/PUR. Возможная толщина наших сэндвич панелей 40 — 300 мм. Цвет любой по каталогу RAL. Тел.: +74991105171
-
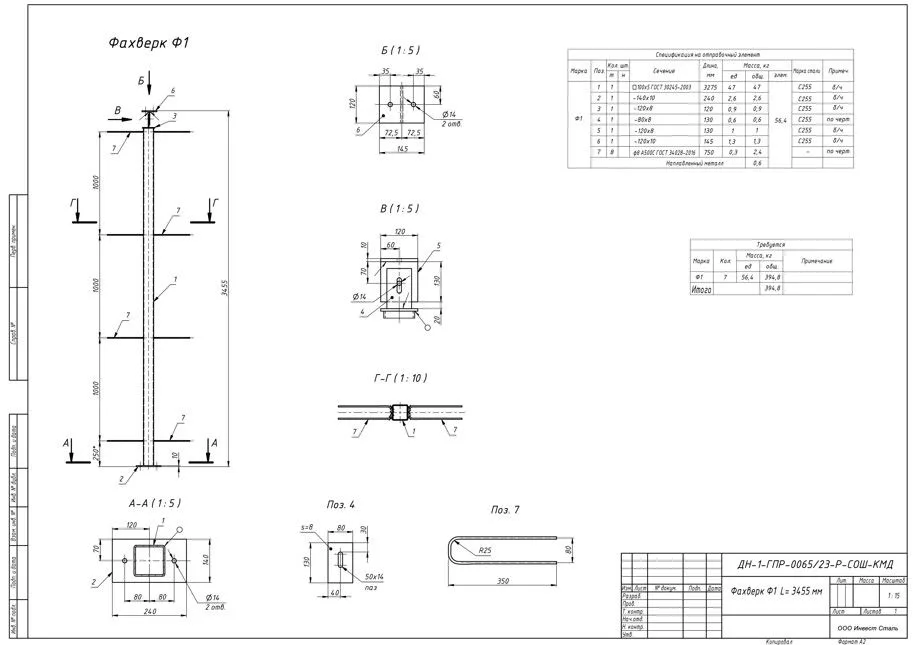
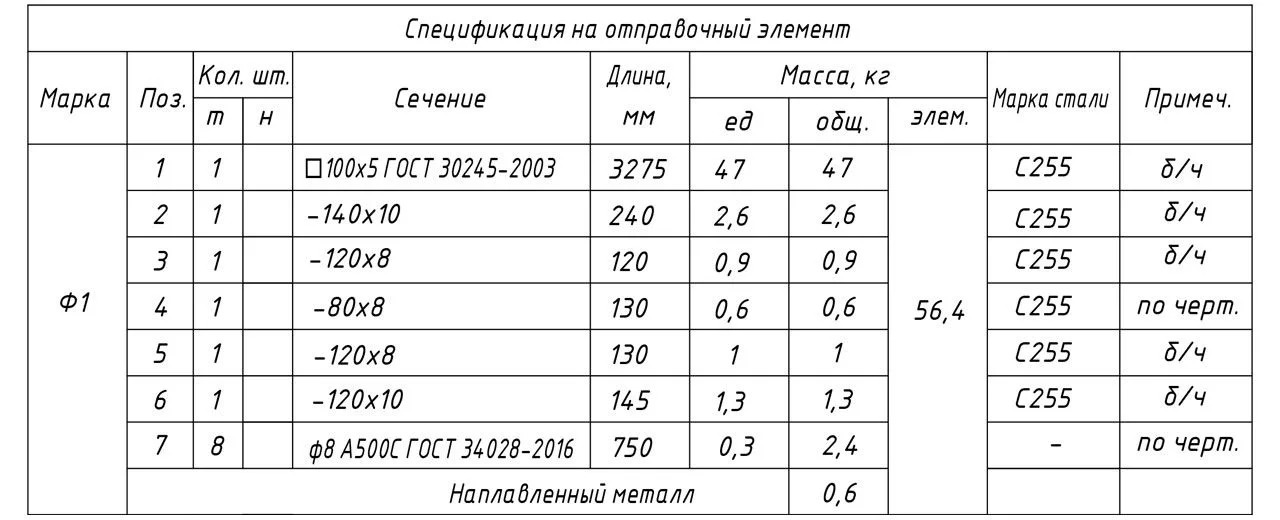
 +5Как перевести чертежи КМД в реальные деньги: пошаговый расчёт стоимости металлоконструкций на примере стойки фахверка
+5Как перевести чертежи КМД в реальные деньги: пошаговый расчёт стоимости металлоконструкций на примере стойки фахверкаВсем, кто хоть раз составлял смету или закупал металлопрокат, знакома эта головная боль: на руках - чертёж КМД, а как из него выжать понятные цифры по материалам и изготовлению?
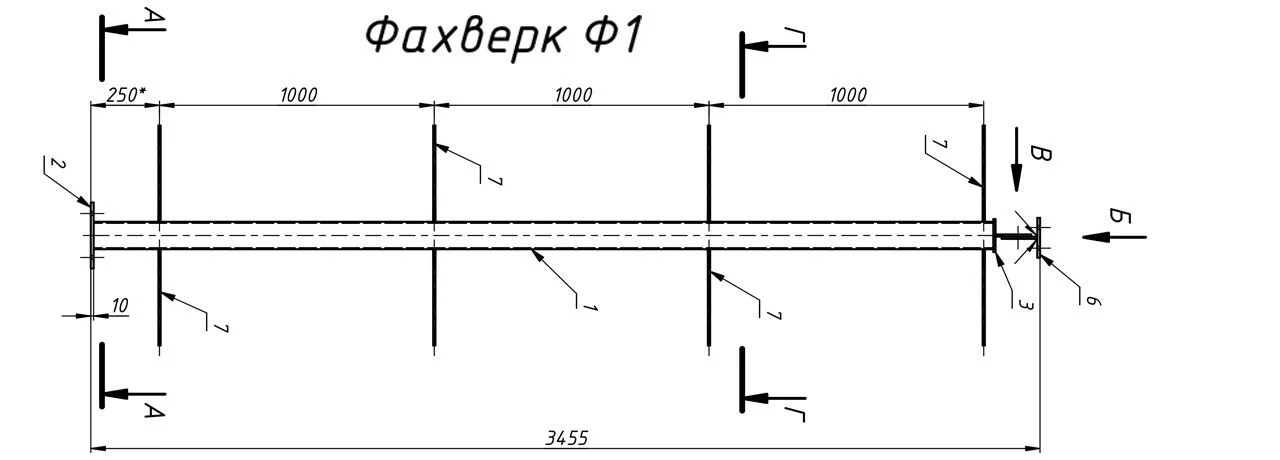
Сегодня мы пройдём весь путь от спецификации до финальной цены на живом примере - стойки фахверка Ф1 длиной 3455 мм, партия 7 штук.
Статья предназначена - для производителей, снабженцев и проектировщиков, которые хотят разобраться в ценообразовании 2026 года без лишней воды.
Шаг 1. Вникаем в спецификацию КМД и находим «скрытые» детали
Первая точка опоры - чертежи. Наша задача - выловить массу каждой детали и вес проката по отдельности. Открываем таблицу «Спецификация на отправочный элемент» и суммируем.
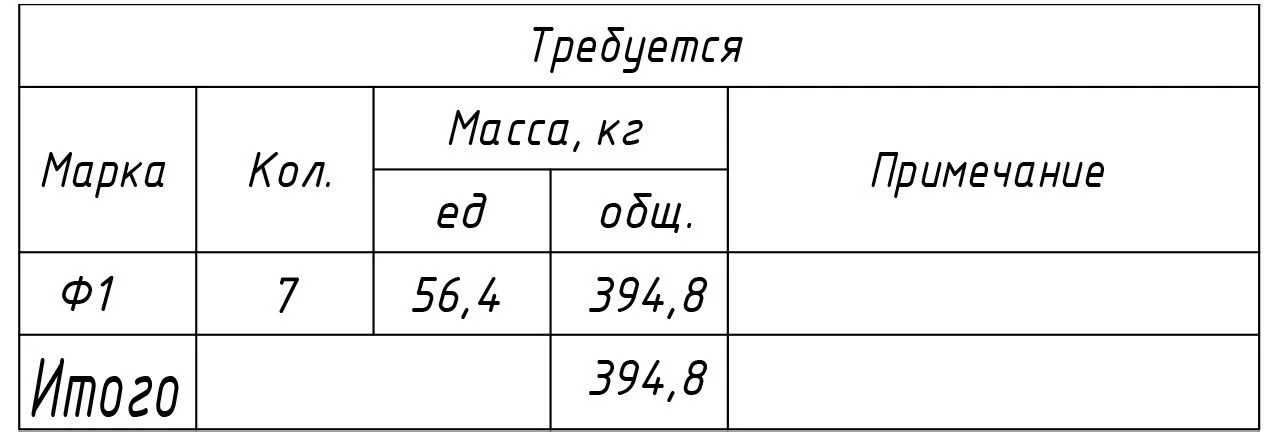
Общий тоннаж на всю партию (7 шт):
56,4 кг × 7 = 394,8 кг.Конструкция у нас состоит из:
- основного несущего стержня (труба 100×5, поз. 1),
- набора косынок и рёбер из полос (поз. 2–6),
- арматуры (поз. 7).
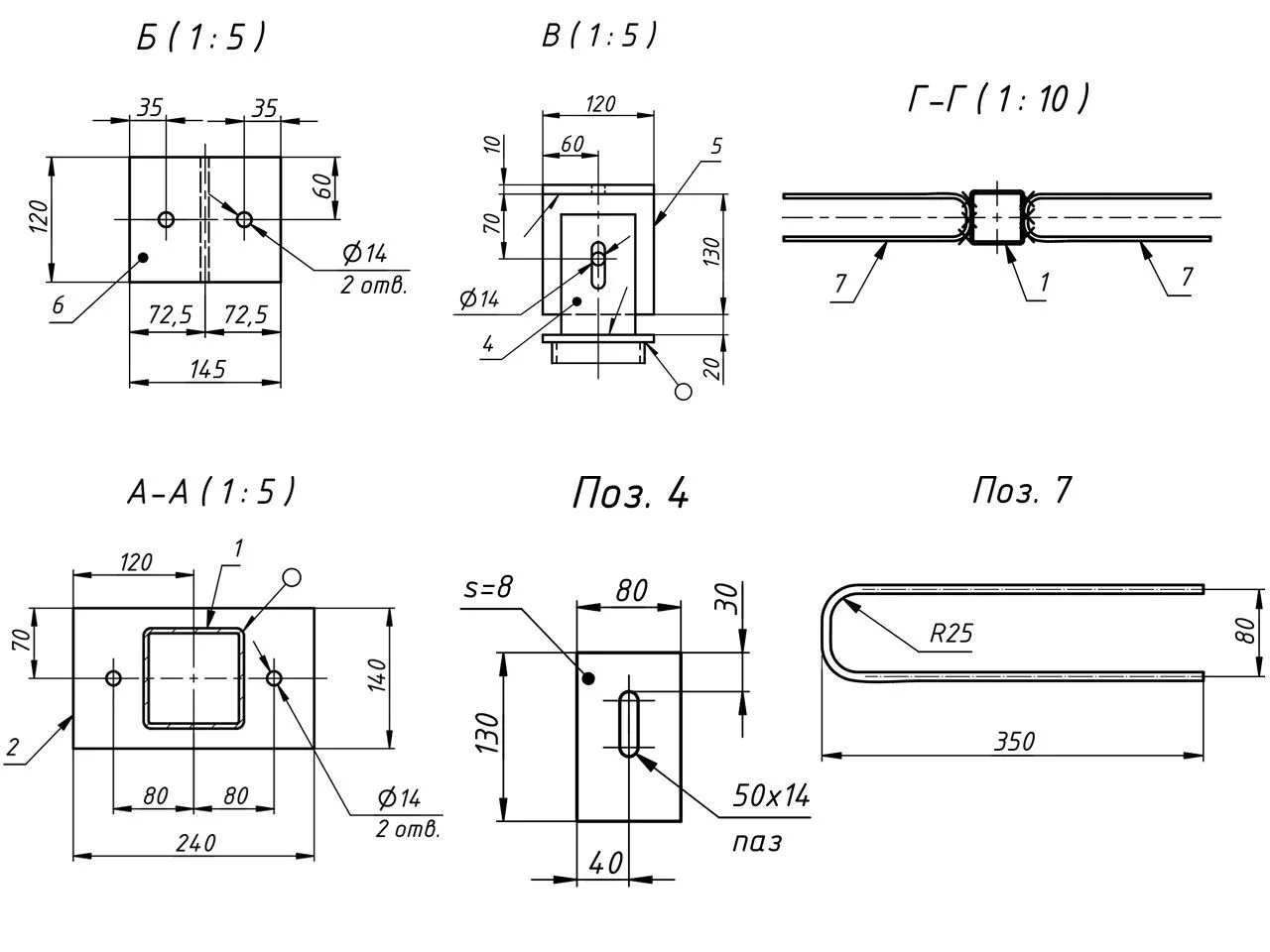
 ️ Важнейшее правило: никогда не смотрите только на общий вес! Обязательно изучайте узлы и разрезы (в нашем случае - А-А, Б-Б, В, Г-Г). Именно там прячутся мелкие детали, пазы и фаски — они требуют дополнительного времени резчиков, а значит, напрямую влияют на стоимость работ.
️ Важнейшее правило: никогда не смотрите только на общий вес! Обязательно изучайте узлы и разрезы (в нашем случае - А-А, Б-Б, В, Г-Г). Именно там прячутся мелкие детали, пазы и фаски — они требуют дополнительного времени резчиков, а значит, напрямую влияют на стоимость работ.
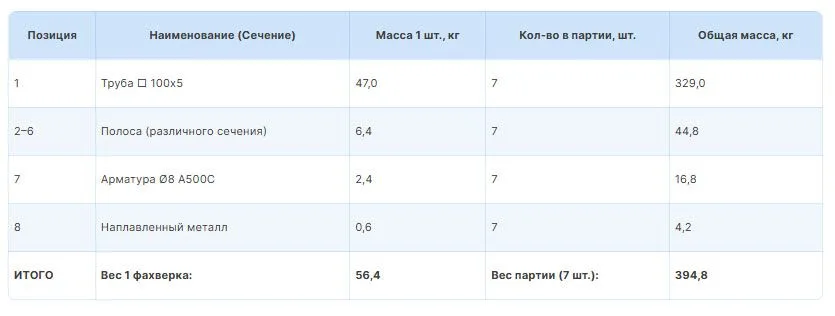
Шаг 2. Считаем теоретический вес каждой позиции
По данным чертежа, распределение веса на одно изделие выглядит так:
Шаг 3. Рассчитываем стоимость материала (металлопрокат)
Умножаем массу каждой позиции на среднерыночную цену за тонну с НДС (ориентируемся на котировки металлсервиса).
В 2026 году средние цены сложились следующие:
Материал Цена за тонну, ₽ Труба профильная 67 000 (диапазон 67–70 тыс.) Полоса стальная 60 000 (диапазон 60–63 тыс.) Арматура А500С 69 000 (диапазон 69–73 тыс.) Бюджет на материал для 1 штуки:
- Труба: 0,047 т × 67 000 ₽ = 3 149 ₽
- Полоса: 0,0064 т × 60 000 ₽ = 384 ₽
- Арматура: 0,0024 т × 69 000 ₽ = 165,6 ₽
 Итого материал на 1 шт: 3 698,6 ₽
Итого материал на 1 шт: 3 698,6 ₽
Материал на 7 изделий: 3 698,6 ₽ × 7 = 25 890,2 ₽ Это «чистый» вес без учёта неликвидов и обрезков. На практике обычно закладывают ещё 1–7% сверху - не забывайте про это!
Это «чистый» вес без учёта неликвидов и обрезков. На практике обычно закладывают ещё 1–7% сверху - не забывайте про это!
Шаг 4. Оцениваем затраты на изготовление
Среднерыночная стоимость изготовления металлоконструкций «под ключ» (раскрой, сварка, зачистка, покраска/АКЗ) - 85 000 ₽ за тонну.
В эту цифру входят: работа сварщиков, аргон, электроды, амортизация оборудования, аренда и маржа.
(У каждого производства своя себестоимость, но для ориентира берём среднее.)Считаем работу:
На всю партию (0,394 т): 0,394 т × 85 000 ₽ = 33 490 ₽
На 1 изделие: 33 490 ₽ / 7 шт = 4 784,28 ₽
Шаг 5. Антикоррозийная защита (покраска)
Площадь поверхности одного фахверка - примерно 1,9 м² (основная часть приходится на трубу + рёбра).
На партию из 7 штук: 1,9 × 7 ≈ 13,3 м².Среднерыночная стоимость системы «грунтовка 3 в 1 / эмаль» - около 600 ₽/м².
На партию: 13,3 м² × 600 ₽ = 7 980 ₽
На 1 изделие: 1 140 ₽
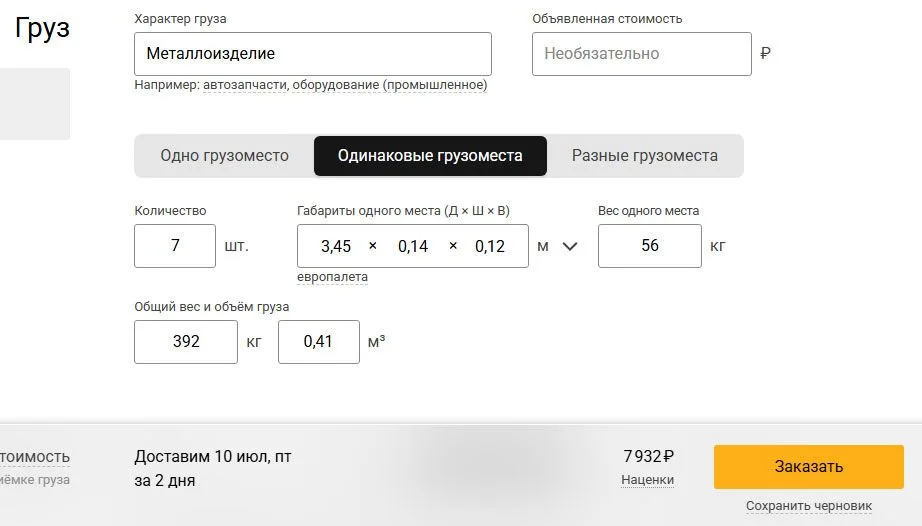
Шаг 6. Логистика
Масса партии - всего 394,8 кг. Такой груз легко увезёт обычная «Газель».
Стоимость рейса по городу / ближней области в среднем - 7 000 ₽.
Логистика на 1 изделие: 7 000 ₽ / 7 шт = 1 000 ₽А если точнее - вот расчёт доставки от Деловых Линий (ориентир для сравнения):
Итоговый бюджет: что получаем на выходе?
Складываем все затраты, чтобы увидеть реальную себестоимость готовой конструкции для заказчика:
Статья затрат Сумма на партию, ₽ Металл 25 890 Изготовление 33 490 Покраска 7 980 Логистика 7 000 ИТОГО за партию (7 шт) 74 360 ₽ Стоимость 1 готового фахверка Ф1: 75 180 ₽ / 7 шт = 10 622 ₽
Резюмируем наш расчёт
Предложенный алгоритм позволяет выйти на бюджет с погрешностью примерно 5–15% от реальной цены.
Но помните: мы не учли сложную логистику, нестандартные конструктивные решения, процент отходов металла, колебания биржевых цен на прокат и прочие расходники. Все эти факторы могут скорректировать финальную цифру.
Хотите заказать изготовление металлоконструкций? Обращайтесь к нам в «Инвест Сталь» - мы поможем и с расчётами, и с качественным производством!
-
Плоский оцинкованный металлопрокат. Лента, лист, рулон!
Добрый день , меня зовут Полетаев Игорь, я руководитель проектов компании “Железный Аргумент”. Мы находимся в городе Липецке, занимаемся поставками плоского, оцинкованного металлопроката. Работаем на базе “ПАО НЛМК” , есть 2 своих производственных цеха.
Режем штрипс-ленту в раскрой от 20 мм, рубим лист длинной до 6м, в наличии оцинкованный металлопрокат толщиной до 4мм и покрытием Zn до 600.
Работаем по всей территории РФ.При предоставлении конкурентного счета, даем гарантию лучшей цены!
Полетаев Игорь Михайлович
Руководитель проектовЖЕЛЕЗНЫЙ АРГУМЕНТ
моб. +7(906) 592-55-32
Poletaev@z-argument.ru
-
DRY_RUN что это, где используется и главное для чего
Для всех любителей g-code, fanuc и всего-всего чпушного.
Если кто знает что такое
dry_run- отлично, кто не знает - ничего страшного сейчас объясню")
DRY_RUN - это такой режим пробного прогона, выполнение программы или команды при котором логина проверяется на симулятор, но реальные изменения не производятся.
Где используется:
- конечно же наши любые ЧПУ (Fanuc и прочие)
- инфраструктура в terraform системах, CI/CD
- скриптах shell и bash
- cli инструментах
Да и вообще везде где только можно, как правило в ЧПУ это уже вшитые системы, а вот в коде мы их пишем сами, к примеру:
DRY_RUN = true // только проверяем, не выполняем if (DRY_RUN) { // что-то проверяется } else { // что-то уже выполняется }Проще говоря простая проверка на булево значение
trueилиfalseНа заметку:
DRY_RUNв ЧПУ - встроенная функция стойки (аппаратный уровень), а в коде это паттерн (шаблон)
-


 Любовь на высоте: как 54 400 тонн стали стали свидетелями предложения руки и сердца
Любовь на высоте: как 54 400 тонн стали стали свидетелями предложения руки и сердца1 июля 2026 года двое руферов из России - Ангелина Николау и Иван Кузнецов (известный как Иван Биркус) - тайно проникли через технический люк на шпиль Эмпайр-стейт-билдинг в Нью-Йорке.
На высоте аж 443 метра Иван встал на колено и сделал Ангелине предложение, после чего пара развернула баннер с посланием о мире. Спуск закончился встречей с полицией и конечно же паре предъявили восемь обвинений, включая незаконное проникновение и создание угрозы жизни.
Но меня больше интересует на чем именно они стояли. И вот тут начинается настоящая красота инженерии, про которую я не знал и пошел в википедию* (сами пояндексите) почитать.
Пару фактов о конструкции, которая пережила предложение :
- Стальной каркас здания весит 54 400 тонн - это примерно 3600 железнодорожных вагонов металла, уложенных в форму небоскрёба.
- При этом сталь составляет лишь 16% от общей массы здания в 331 000 тонн - остальное бетон, стекло и отделка.
- Высота до кончика шпиля - 443,2 метра, до крыши - 381 метр; разница в 62 метра - это чисто металлическая антенная конструкция, на которую и забралась пара.
- Здание построили за 410 дней во времена Великой депрессии (кстати ее и не было) - рекордные темпы возведения стального каркаса небоскрёба до сих пор считаются эталоном скорости строительства.
- Ширина основания - около 140 метров, что даёт зданию устойчивость, которая, видимо, выдержала не только ветровые нагрузки, но и незаконного визитёра с кольцом в кармане.
*По данным Роскомнадзора, в отношении „Википедии“ применяются меры понуждения в связи с нарушением российского законодательства
-
Нержавеющий круг 30Х13: состав, применение и выбор вида обработки
Нержавеющий прокат круглого сечения из стали марки 30Х13 востребован в машиностроении, пищевой промышленности и производстве режущего инструмента. Материал сочетает высокую твёрдость, износостойкость и умеренную коррозионную стойкость, что делает его оптимальным решением для ответственных деталей, работающих в условиях трения и переменных нагрузок.
Химический состав и механические свойства сплава
Марка 30Х13 относится к мартенситному классу нержавеющих сталей. Цифробуквенное обозначение расшифровывается просто: «30» указывает на содержание углерода около 0,30%, а «Х13» — на долю хрома примерно 13%. Такой баланс легирующих элементов формирует структуру, способную после закалки и отпуска достигать твёрдости 48–55 HRC.
Прокат изготавливается в строгом соответствии с нормативами, поэтому круг 30х13 ГОСТ гарантирует стабильные механические показатели: предел прочности при растяжении не менее 600 МПа, относительное удлинение от 15%, ударную вязкость и устойчивость к истиранию. Материал хорошо поддаётся термообработке, но требует аккуратной сварки из-за склонности к закалочным напряжениям.
Круг или пруток: как правильно называть и где применяется
В технической среде и коммерческих каталогах часто возникает вопрос: что вернее — «круг» или «пруток»? На практике оба термина корректны и используются как синонимы. Слово «круг» описывает геометрию поперечного сечения, а «пруток» — форму поставки сортового проката. Поэтому запись «Круг стальной нержавеющий Ст30Х13» или «пруток из стали 30Х13» абсолютно равнозначна и соответствует отраслевой практике.
Сталь 30х13 круг применяется для изготовления:
- валов, осей, шпинделей и втулок;
- ножевых блоков, лезвий и режущих элементов;
- арматуры, запорных клапанов и деталей насосов;
- крепёжных изделий, пружин и элементов пищевой техники.
Благодаря способности сохранять свойства при контакте с пищевыми средами и умеренно агрессивными жидкостями, материал широко используется в оборудовании для переработки продуктов и химической промышленности.
Круг калиброванный нержавеющий
Круг калиброванный нержавеющий проходит дополнительную холодную протяжку через калибровочные отверстия или ролики. Эта операция устраняет окалину, выравнивает геометрию и доводит поверхность до состояния металлического блеска. Допуски по диаметру сужаются до классов точности h9–h11, а шероховатость снижается до Ra 0,8–1,6 мкм.
Главное преимущество калиброванного проката — полная готовность к механической обработке на станках ЧПУ. Детали вытачиваются без черновых операций, что сокращает время производства, уменьшает износ резцов и повышает точность конечного изделия. Такой вариант оптимален для прецизионных узлов, подшипниковых посадок и ответственных соединений.
Круг обточенный нержавеющий
Круг обточенный нержавеющий представляет собой горячекатаную или кованую заготовку, которая проходит механическую обточку на токарных станках. Процедура удаляет поверхностную окалину, выравнивает отклонения от круглости и улучшает внешний вид по сравнению с чёрным прокатом. Допуски обычно соответствуют классам h12–h14, что делает материал доступным по стоимости и удобным для серийного производства.
Обточенный прокат выбирают, когда не требуется прецизионная точность на входе, а деталь будет проходить последующую фрезеровку, сверление или шлифовку. Он идеально подходит для изготовления валов общего назначения, втулок, крепёжных элементов, заготовок под штамповку и деталей, работающих в условиях умеренного износа.
Купить нержавеющий круг 30х13
Если вам необходимо круг 30х13 купить с гарантией качества и полным пакетом документов, компания МК Ферро предлагает калиброванный и обточенный прокат в широком диапазоне диаметров. Мы обеспечиваем точный рез под ваши чертежи, предоставляем сертификаты соответствия и оперативную доставку по всей России. Оставьте заявку на сайте или свяжитесь с менеджерами — специалисты помогут подобрать оптимальный вид обработки, рассчитают стоимость и оформят заказ в кратчайшие сроки.
-
Пруток круглый нержавеющий: виды, марки стали и сферы применения
Что такое пруток круглый нержавеющий и где он применяется
Пруток круглый нержавеющий представляет собой сплошной сортовой металлопрокат круглого сечения, обладающий высокой коррозионной стойкостью и прочностью. Благодаря отсутствии внутренних полостей и однородной структуре, он служит идеальной базовой заготовкой для дальнейшего механического обработки и изготовления ответственных деталей.Основные сферы использования металлопроката
Пруток нержавеющий востребован там, где требуется долговечность и устойчивость к агрессивным средам. Из него вытачивают валы, оси, втулки, шпиндели, элементы крепежа и запорной арматуры. Материал незаменим в пищевой и химической промышленности, машиностроении, судостроении, а также в архитектурном дизайне для создания декоративных и несущих конструкций.Марки стали: от AISI 201 до 40х13
Сортамент продукции включает как международные, так и отечественные стандарты. Круг нержавеющий aisi 201, 304 и 321 относится к аустенитному и аустенитно-стабилизированному классу, обеспечивая отличную свариваемость и пластичность. Российские марки 14х17н2, 20х13, 30х13 и 40х13 относятся к мартенситному и ферритному классам. Они отличаются повышенной твердостью и прочностью после термической обработки, что делает их идеальными для производства режущего инструмента, рессор и деталей, работающих на износ. Пруток нержавеющий aisi и его российские аналоги подбираются строго под условия эксплуатации будущей детали.Характеристики нержавеющего прутка aisi 304
Нержавеющий круг 304 (аналог 08Х18Н10) — самый популярный вид проката благодаря универсальности. Характеристики нержавеющего прутка aisi 304 включают высокую стойкость к межкристаллитной коррозии, отличную обрабатываемость резанием и сохранение механических свойств при низких температурах. Именно поэтому круг калиброванный нержавеющий aisi 304 так часто применяется для производства оборудования для пищевой промышленности и медицинских учреждений.Типы поверхности и особенности обработки
Внешний вид и точность геометрии прутка зависят от метода его финишной обработки. На рынке представлены два основных типа поверхности, каждый из которых имеет свои технологические преимущества и сферу применения.Калиброванный и обточенный прокат: в чем разница?
Пруток калиброванный нержавеющий производится методом холодной деформации (протяжки) через калибровочные отверстия. Это позволяет получить идеально гладкую поверхность, металлический блеск и высочайшую точность диаметра с минимальными допусками. Такой прокат не требует дополнительной черновой обработки и сразу готов к чистовому точению на станках ЧПУ. Обточенный пруток получают путем снятия верхнего слоя (окалины) на токарных станках. Он имеет матовую поверхность и чуть большие допуски, но стоит дешевле, что оптимально для изготовления деталей с последующей глубокой механической обработкой.Геометрические параметры и стандарты производства
Для удобства логистики и оптимизации производственного процесса прокат выпускается в строго определенных геометрических форматах. Подбор правильного сечения и длины позволяет минимизировать отходы металла при раскрое.Стандарты длины и диаметра
Современный металлопрокат покрывает практически любые производственные нужды. Диаметр круга (прутка) варьируется от 4 до 360 мм, что позволяет использовать его как для миниатюрных крепежных элементов, так и для массивных валов промышленного оборудования. Стандартная длина мерных прутков составляет 3000 и 6000 мм. Такие габариты удобны для транспортировки, складского хранения и автоматизированной резки в размер на ленточнопильных станках.Купить Пруток круглый нержавеющий в Нижнем Новгороде
Если вам необходим качественный сортовой прокат для производства, компания МК Ферро предлагает широкий ассортимент нержавеющих кругов и прутков всех востребованных марок стали. Мы поставляем калиброванный и обточенный прокат диаметром от 4 до 360 мм длиной 3000 и 6000 мм. В наличии на складе всегда есть нержавеющий круг 304, а также марки AISI 201, 321, 40х13, 30х13 и другие.Мы гарантируем строгое соответствие ГОСТ, предоставляем сертификаты качества и предлагаем услуги резки в размер. Оформить заказ или получить консультацию специалиста вы можете в нашем каталоге - Круг нержавеющий
Работаем с предприятиями Нижнего Новгорода и отправляем заказы транспортными компаниями по всей России.
-




 +2Обечайки из листового металла: от древнего слова до современных технологий
+2Обечайки из листового металла: от древнего слова до современных технологийОгромный нефтяной резервуар высотой с десятиэтажный дом, внутри которого под огромным давлением находится тысячи тонн жидкости. Или гигантская ректификационная колонна на нефтеперерабатывающем заводе. Или барабан парового котла, вырабатывающего энергию для целого города.
Что общего у всех этих конструкций? Их основу составляют обечайки - незаметные, но критически важные элементы, без которых современная промышленность просто немыслима.
Откуда взялось слово «обечайка»? Этимология, уходящая впрошлое
Мало кто задумывается, но слово «обечайка» имеет древние корни, уходящие в глубь веков. Его происхождение - это настоящий лингвистический детектив.
Согласно этимологическому словарю Макса Фасмера, слово происходит от *обвитъчайка - то есть от корня «вить» (как вить веревку, плести) и приставки «об-» (вокруг).
Получается, что обечайка в буквальном смысле - это «то, что обвито вокруг» или «оплетка».
И действительно, в прошлом обечайками называли лыковые ободы на ситах, решетах и жерновах - те самые деревянные или плетеные кольца, которые «обвивали» сито по кругу, придавая ему форму и прочность. В украинском языке до сих пор существует слово «обичайка» с тем же значением.
А вы знали, что обечайка - это еще и боковая часть корпуса музыкальных инструментов? Да, та самая изогнутая стенка гитары, скрипки или виолончели, которая соединяет верхнюю и нижнюю деки, тоже называется обечайкой. И у барабанов обечайка есть - ее называют «кадло».
Таким образом, слово «обечайка» объединяет в себе сотни лет истории: от плетеного обода крестьянского решета до высокотехнологичной детали космического корабля или корпуса атомного реактора. И во всех случаях смысл остается неизменным - это кольцевой элемент, который «обвивает» конструкцию, придавая ей форму, прочность и целостность.
Что такое обечайка в современном понимании?
В современной промышленности обечайка - это открытый с торцов цилиндрический или конический элемент, изготовленный из листового металла путем вальцовки (гибки) и последующей сварки.
Если говорить максимально просто: обечайка - это свернутый в кольцо лист металла. Как лист бумаги, который вы свернули в трубочку и склеили края. Только вместо бумаги - сталь толщиной от нескольких миллиметров до десятков сантиметров, а вместо клея - сварной шов высочайшего качества.
Эти, казалось бы, простые кольца являются основой для огромного количества оборудования. Именно из обечаек, собранных встык и сваренных между собой, собираются стенки резервуаров, корпуса реакторов, кожухи теплообменников и секции трубопроводов.
Технология изготовления: как рождается обечайка
Производство обечайки - это сложный высокотехнологичный процесс, состоящий из нескольких ключевых этапов. Каждый из них требует высокой точности, современного оборудования и квалифицированных специалистов.
Основные этапы производства:
Этап Описание Важность 1. Раскрой листа Листовой металл нарезается на заготовки точных размеров с использованием плазменной, газовой или лазерной резки Обеспечивает точные геометрические параметры будущей обечайки 2. Подготовка кромок Края заготовки обрабатываются под сварку Критически важно для качества сварного шва 3. Вальцовка (гибка) Заготовка пропускается через трех- или четырехвалковые станки, где под давлением валков приобретает цилиндрическую или коническую форму Самый ответственный этап — от него зависит геометрия изделия 4. Сварка Кромки свернутого листа свариваются продольным швом. При сборке нескольких поясов выполняются и кольцевые швы Обеспечивает герметичность и прочность конструкции 5. Калибровка Готовое изделие проходит калибровку для устранения овальности и достижения точных размеров Гарантирует соответствие заданному диаметру 6. Контроль качества Проверка геометрии, сварных швов (визуально, измерительно, методами неразрушающего контроля) Обеспечивает безопасность и надежность Заказать изготовление обечаек в нашей компании — значит получить изделие, прошедшее все этапы контроля качества в соответствии с требованиями ГОСТ и отраслевых стандартов.
Холодная и горячая вальцовка
Важный нюанс технологии: при толщине листа до 40 мм применяется холодная вальцовка. Для толстостенных изделий используются мощные станки, иногда с предварительным подогревом заготовок («горячая» вальцовка). Это позволяет работать с металлом большой толщины, сохраняя качество гибки и предотвращая появление трещин.
Виды обечаек: форма определяет функцию
Обечайки классифицируются по нескольким признакам. Выбор типа обечайки напрямую зависит от ее назначения и условий эксплуатации.
По геометрической форме:
Тип Описание Основное применение Цилиндрические Прямые кольцевые элементы с постоянным диаметром по всей длине Стенки резервуаров, емкостей, трубные вставки, кожухи аппаратов Конические Элементы с переменным диаметром, сужающиеся или расширяющиеся Переходные элементы между разными диаметрами, воронки, бункеры, разгрузочные узлы Секционные Собираются из нескольких сегментов-лепестков Особо крупные диаметры (свыше 3 метров) и нестандартные конструкции Каждый тип имеет свои особенности в расчете и технологии изготовления. Для цилиндрических обечаек критически важны устойчивость к внутреннему давлению и минимальные отклонения по овальности. Для конических - точность угла и качество стыковки с соседними элементами.
По конструкции:
- Однослойные - классический вариант, наиболее распространенный.
- Многослойные (с рубашкой) - две обечайки разного диаметра, вложенные друг в друга. Используются в сосудах под давлением для обогрева или охлаждения.
- Сварные из лепестков - собираются из нескольких секторов при очень больших диаметрах.
Материалы: от углеродистой стали до специальных сплавов
Выбор материала для обечайки - это вопрос безопасности и долговечности всего оборудования. Неправильно подобранная марка стали может привести к катастрофическим последствиям: от утечек и аварий до полного разрушения конструкции.
Основные материалы для изготовления обечаек:
Материал Марки Характеристики Область применения Углеродистая сталь Ст3, сталь 20 Универсальная, доступная, хорошая свариваемость Резервуары и конструкции общего назначения Низколегированная сталь 09Г2С, 17Г1С Повышенная прочность, устойчивость к низким температурам Повышенные нагрузки, северные условия Нержавеющая сталь 12Х18Н10Т, AISI 304/316 Коррозионная стойкость, санитарная безопасность Пищевая, химическая, фармацевтическая промышленность, агрессивные среды Цветные сплавы Алюминиевые, медные сплавы Легкость, специальные свойства Специальные аппараты и легкие конструкции Особое внимание уделяется соответствию материала и толщины требованиям ГОСТ и профильных стандартов, особенно при работе с аппаратами под давлением.
Мы изготавливаем обечайки на заказ из любых марок стали, включая специальные - по индивидуальным требованиям проекта. Подробнее.
Где применяются обечайки? Практически везде!
Обечайки - это универсальный строительный блок современной промышленности. Их применение охватывает десятки отраслей.
Отрасли применения:
- Нефтегазовая промышленность - корпуса сепараторов, абсорберов, ректификационных колонн, резервуары для хранения нефтепродуктов и газов
- Химическая промышленность - реакторы, колонны, теплообменники, емкости для агрессивных сред
- Энергетика - барабаны паровых котлов, корпуса турбин, конденсаторы
- Пищевая промышленность - бродильные чаны, пастеризаторы, емкости для хранения продуктов
- Строительство - опоры мостов, колонны, дымовые и вентиляционные трубы
- Водоподготовка и ЖКХ - напорные резервуары для воды, отстойники
Конкретные конструкции:
- Резервуары и емкости для хранения воды, нефтепродуктов, химических сред
- Корпуса технологических аппаратов, колонн и кожухов теплообменников
- Секции трубопроводов, переходы, вставки и защитные оболочки
- Элементы дымовых труб, газоходов и воздуховодов
- Части цилиндрических и конических металлоконструкций в строительстве
Стандарты и требования к качеству
Производство обечаек строго регламентируется государственными стандартами. Это не просто формальность - это вопрос безопасности жизни и здоровья людей.
Основные нормативные документы:
- ГОСТ 25215-82 - «Сосуды и аппараты высокого давления. Обечайки и днища. Нормы и методы расчета на прочность»
- ГОСТ Р 52857.2-2007 - «Сосуды и аппараты. Нормы и методы расчета на прочность»
- ГОСТ Р 52630-2012 - общие требования к сосудам и аппаратам
Ключевые параметры контроля:
- Геометрия: диаметр, овальность, прямолинейность кромок, длина
- Сварные швы: визуальный, измерительный контроль и неразрушающие методы (ультразвук, радиография)
- Калибровка: точное соответствие рабочим размерам
- Документация: протоколы контроля, паспорта, сертификаты материалов
Для сосудов и резервуаров под давлением дополнительно выполняются расчеты по прочности, испытания и расширенный контроль швов.
Что влияет на стоимость изготовления обечаек?
Понимание факторов ценообразования поможет вам оптимизировать бюджет при заказе.
Основные факторы:
Фактор Влияние на стоимость Марка стали и толщина листа Чем толще и качественнее металл - тем выше стоимость Диаметр, длина и тип обечайки Конические и секционные сложнее в изготовлении Требования к контролю швов Расширенный контроль (ультразвук, рентген) увеличивает затраты Дополнительная обработка Обработка торцов, защитные покрытия, антикоррозионная защита Объем партии Серийные заказы снижают стоимость за счет оптимизации Корректно составленное техническое задание помогает быстро получить точный расчет и оптимизировать бюджет. А также мы создали калькулятор обечаек для упрощения расчета стоимости.
Как заказать изготовление обечаек в нашей компании?
Мы предлагаем полный цикл производства обечаек - от разработки чертежей до отгрузки готовых изделий.
Процесс заказа:
- Подготовьте чертежи или техническое задание с указанием диаметра, длины, толщины стенки, марки стали и требований к контролю
- Передайте данные для расчета стоимости и выбора оптимальной технологии
- Согласуйте коммерческое предложение, сроки и условия выполнения заказа
- Запустите заказ в производство - при необходимости организуйте контроль ключевых этапов
- Получите готовые обечайки и используйте их в составе резервуаров, емкостей и металлоконструкций
 Совет: чем полнее исходная информация, тем быстрее мы сможем подобрать технологию, рассчитать стоимость и согласовать сроки. При необходимости наши специалисты предложат рекомендации по оптимизации толщины, конструкции и схемы раскроя.
Совет: чем полнее исходная информация, тем быстрее мы сможем подобрать технологию, рассчитать стоимость и согласовать сроки. При необходимости наши специалисты предложат рекомендации по оптимизации толщины, конструкции и схемы раскроя.Преимущества обечаек из листового металла
Почему обечайки из листового металла стали стандартом в промышленности?
Преимущество Пояснение Высокая прочность Способность выдерживать огромное внутреннее и наружное давление Герметичность Качественный сварной шов обеспечивает полную герметичность Долговечность При правильной антикоррозионной обработке - десятилетия службы Универсальность Возможность изготовления практически любого диаметра и конфигурации Экономичность Производство из листового металла дешевле литья или ковки Адаптивность Индивидуальное изготовление по чертежам заказчика Подводим итоге
Обечайка - это не просто кусок свернутого металла. Это - результат тысячелетней эволюции: от плетеного обода крестьянского решета до высокотехнологичного элемента современных нефтяных вышек, химических реакторов и космических кораблей.
Слово, пришедшее к нам из глубины веков от корня «вить» - «обвивать вокруг», - сегодня обозначает основу современной промышленности. Без обечаек не было бы ни огромных резервуаров для хранения нефти, ни сложных химических производств, ни надежных трубопроводов, по которым текут энергоносители по всей планете.
Нужны качественные обечайки? Закажите их у нас! info@investsteel.ru
Наши специалисты помогут подобрать оптимальный материал, рассчитать стоимость и изготовить изделия, которые прослужат десятилетия. Свяжитесь с нами - и мы сделаем надежную основу для вашего оборудования.
-
Строительство домов и благоустройство участка под ключ
От строительства домов до благоустройства участка — [https://artyukhov-stroi.ru/](Адрес ссылки) охватывает всё. Мы специализируемся на строительстве домов под ключ и услугах по ландшафтному дизайну. Чтобы показать как примеры, доступны несколько завершённых проектов, сроки всегда соблюдаются. Работаем надёжно и профессионально.
-
 Резервуары рвс что это такое - расшифровка
Резервуары рвс что это такое - расшифровкаРВС - это аббревиатура, которая расшифровывается как Резервуар Вертикальный Стальной. Это один из самых распространенных типов емкостей для хранения жидкостей.
Что такое РВС и для чего он нужен?
РВС (резервуар вертикальный стальной) - это наземное цилиндрическое сооружение, предназначенное для приема, хранения и выдачи жидких продуктов, преимущественно нефти и нефтепродуктов.
Эти резервуары играют ключевую роль в нефтяной и химической промышленности и используются для решения следующих задач:
- Прием и хранение: сырой нефти, мазута, дизельного топлива, керосина, масел, битума и других жидких продуктов.
- Обеспечение бесперебойности: компенсация неравномерности в поступлении и отгрузке продуктов на нефтеперекачивающих станциях и нефтебазах.
- Учет продукта: резервуары являются средствами измерений объема жидкостей.
Конструктивные особенности
- Форма: Представляют собой вертикальную цилиндрическую емкость.
- Материал: Свариваются из стальных листов толщиной 10-25 мм.
- Строение: Корпус состоит из нескольких горизонтальных рядов листов, называемых поясами. Днище резервуара обычно имеет уклон к центру для сбора подтоварной воды.
- Крыша: РВС имеет стационарную (неподвижную) крышу, которая может быть конической или сферической.
- Давление: Это резервуары низкого («атмосферного») давления (не более 0,002 МПа или 0,02 атм).
Классификация РВС
Резервуары типа РВС классифицируются по нескольким параметрам.
1. По номинальному объему (вместимости): Самый распространенный способ идентификации. Обозначение типа резервуара всегда включает его объем в кубических метрах (м³): например, РВС-1000, РВС-2000, РВС-5000, РВС-10000, РВС-20000. Объем может достигать 120 000 м³.
По объему резервуары делятся на классы в соответствии с ГОСТ 31385-2016:
- Класс КС-3а: более 50 000 м³
- Класс КС-3б: от 20 000 до 50 000 м³
- Класс КС-2а: от 1 000 до 20 000 м³
- Класс КС-2б: менее 1 000 м³
2. По конструктивному исполнению крыши: Существуют разные типы вертикальных стальных резервуаров, и аббревиатура уточняет их конструкцию:
Аббревиатура Расшифровка Особенности конструкции РВС Резервуар Вертикальный Стальной Со стационарной крышей и без понтона (плавающего покрытия). РВСП Резервуар Вертикальный Стальной с Понтоном Со стационарной крышей, но внутри есть понтон - плавающее покрытие, которое уменьшает испарение жидкости. РВСПК Резервуар Вертикальный Стальной с Плавающей Крышей Вместо стационарной крыши используется плавающая крыша, которая поднимается и опускается вместе с уровнем жидкости. Нормативная база (проверенные источники)
Проектирование, изготовление и эксплуатация РВС строго регламентируются государственными стандартами. Основные из них:
- ГОСТ 31385-2016: “Резервуары вертикальные цилиндрические стальные для нефти и нефтепродуктов. Общие технические условия”. Это ключевой документ, который устанавливает основные требования к резервуарам.
- ГОСТ Р 58622-2019: Распространяется на резервуары объемом от 100 до 50 000 м³.
- ГОСТ 27751-2014: “Надежность строительных конструкций и оснований”. Определяет классы ответственности сооружений, к которым относятся и резервуары.
Важно знать
РВС - это базовый тип резервуара. Его главная особенность - отсутствие плавающей крыши или понтона. Это делает конструкцию проще и дешевле в обслуживании, но приводит к большим потерям продукта от испарения. Поэтому РВС чаще всего применяют для хранения маловязких и тяжелых продуктов с температурой вспышки более 55°C, например, мазута или битума. Для хранения легких углеводородов (бензина, нефти) чаще используют резервуары типов РВСП и РВСПК, которые позволяют значительно сократить потери от испарения.
https://investsteel.ru/category/rezervuaryi-vertikalnyie-rvs
-
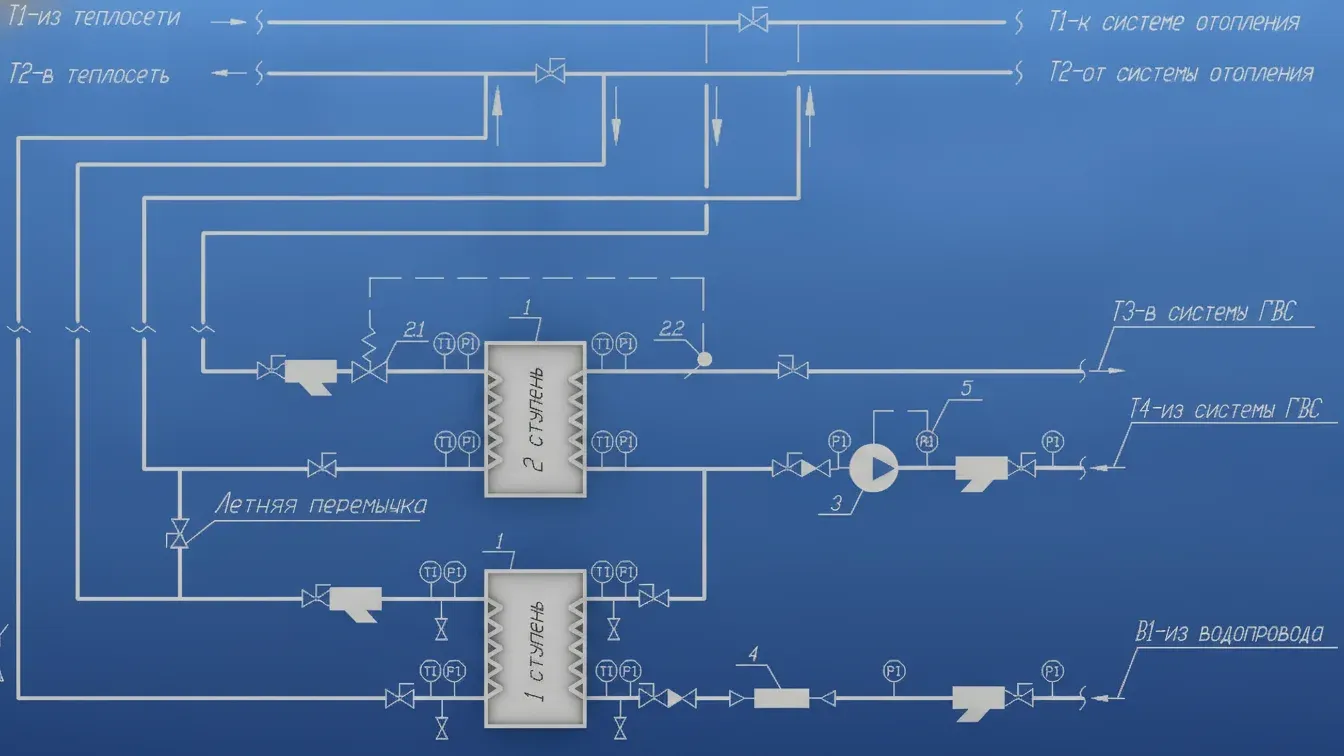 Принцип работы теплообменника в системе отопления и гвс
Принцип работы теплообменника в системе отопления и гвсТеплообменник - это устройство, в котором происходит передача тепла от одной среды к другой. Его главная задача - нагреть холодную воду для отопления или ГВС, используя тепло от уже горячего теплоносителя, без смешивания этих жидкостей.
Принцип работы: как это происходит
Представьте себе, что горячий и холодный потоки жидкости текут навстречу друг другу, но разделены тонкой металлической стенкой. Этот процесс работает на основе простого физического закона: тепло всегда переходит от более горячей среды к более холодной.
- Поступление теплоносителя: Горячая вода (или пар) из системы отопления, котельной или тепловой сети поступает в теплообменник.
- Передача тепла через стенку: Горячий теплоноситель отдает свою тепловую энергию через тонкую, хорошо проводящую тепло металлическую стенку (например, из нержавеющей стали).
- Нагрев холодной воды: Холодная водопроводная вода, проходящая по другую сторону этой стенки, забирает тепло и нагревается до нужной температуры (обычно +60…75 °С).
- Разделение потоков: Важно, что горячий теплоноситель и нагреваемая вода никогда не смешиваются. Они движутся по своим собственным, герметичным каналам.
Основные виды теплообменников
В системах отопления и ГВС чаще всего используются два основных типа устройств:
-
Пластинчатый теплообменник: Это самый распространенный тип для жилых и общественных зданий. Он состоит из множества тонких гофрированных металлических пластин, собранных в пакет. Горячая и холодная жидкости проходят между пластинами поочередно. К его преимуществам относятся компактность (в 2-3 раза меньше кожухотрубных), высокая эффективность и возможность легко увеличить мощность, добавив пластины. Пластинчатые теплообменники могут быть разборными (для обслуживания и чистки) и паяными (более компактными и герметичными).
-
Кожухотрубный теплообменник: Это более старая и массивная конструкция. Она представляет собой большой корпус («кожух»), внутри которого находится пучок тонких трубок. Один теплоноситель течет по трубкам, а другой - в пространстве между ними внутри кожуха. Чаще применяется в промышленности, но может использоваться и в бытовых системах.
Нормативная база
Проектирование и эксплуатация теплообменников регламентируются рядом нормативных документов, среди которых можно выделить:
- СП 41-101-95: Свод правил по проектированию и строительству тепловых пунктов.
- ГОСТ 12.2.003-91: Общие требования безопасности к производственному оборудованию.
- ГОСТ 31385-2016: Хотя этот стандарт в основном касается резервуаров, он показывает общий подход к нормированию в этой области.
Почему нельзя использовать воду из отопления для бытовых нужд?
Этот вопрос часто возникает, и теплообменник является ключевым элементом, который делает разделение контуров обязательным и безопасным. Причин несколько:
- Химическая подготовка: Вода в системе отопления проходит сложную химическую подготовку для защиты труб от коррозии и накипи. Она содержит реагенты, которые могут быть вредны для здоровья при попадании в организм.
- Техническое состояние: За долгие годы эксплуатации в трубах и радиаторах накапливаются различные отложения и продукты коррозии, что делает эту воду непригодной для питья и мытья.
Использование теплообменника решает эту проблему: он использует тепло от «технической» воды, но физически разделяет потоки, обеспечивая вас чистой и безопасной горячей водой из-под крана.
-
 Обичайка или обечайка
Обичайка или обечайкаПравильный вариант написания - обечайка. Вариант «обичайка» является орфографической ошибкой. Это подтверждается авторитетными словарями и справочниками русского языка.
Что означает слово «обечайка»
Это технический термин, который обозначает боковую стенку цилиндрического или конического предмета (сосуда, барабана, трубы). Проще говоря, это «оболочка» изделия, которая обычно не имеет дна и крышки.
Где используется обечайка
Этот элемент конструкции широко применяется в самых разных областях:
- В технике и производстве: как заготовка для изготовления котлов, резервуаров, баков и других металлических емкостей.
- В музыкальных инструментах: как боковая часть корпуса гитар, скрипок, барабанов и других инструментов.
- В быту и других сферах: как обод для сита, решета, лукошка или жернова.
Почему возникает путаница
Ошибка «обичайка» возникает из-за того, что это слово исторически связано с глаголом «обвивать» (что-то, что обвивает, окружает). Однако в современном русском языке нормативным и единственно правильным является написание через букву «е» - обечайка.
Таким образом, запомнить правильный вариант просто: обечайка (с буквой «е» в первом слоге).
-
 Ростверк что это такое
Ростверк что это такоеРостверк - это верхняя часть свайного или столбчатого фундамента, которая объединяет отдельные сваи или столбы в единую, жесткую конструкцию. Его основная задача - равномерно распределять и передавать нагрузку от веса всего здания на сваи, а через них - на грунт.
Простыми словами, если сваи - это “ноги” фундамента, то ростверк - это “пояс”, который связывает их воедино и служит надежной опорой для стен вашего дома.
Основные функции ростверка
- Объединение свай: Связывает отдельные опоры в единую пространственную систему, предотвращая их независимое смещение.
- Распределение нагрузки: Принимает вес здания и равномерно распределяет его между всеми сваями.
- Обеспечение устойчивости: Препятствует опрокидыванию и горизонтальным сдвигам фундамента, повышая общую жесткость конструкции.
Из чего делают ростверк?
В современном строительстве используются следующие материалы:
- Железобетон (монолитный или сборный): Самый распространенный и надежный вариант для капитальных зданий.
- Бетон: Используется для менее нагруженных конструкций.
- Металл (швеллеры, двутавры): Применяется в каркасном строительстве или для усиления существующих фундаментов.
- Дерево (брус): Используется в строительстве деревянных домов, бань и хозпостроек.
Классификация ростверков
Ростверки различают по нескольким ключевым признакам.
1. По месту расположения относительно уровня земли:
Тип ростверка Описание Высокий (висячий) Находится над поверхностью земли на некоторой высоте (например, на винтовых сваях). Позволяет организовать проветриваемое подполье и защищает от подтопления. Низкий Располагается на уровне земли или с небольшим заглублением. Его подошва находится на поверхности грунта. Заглубленный Опущен ниже уровня земли. Такое решение применяется для создания технического подполья или цокольного этажа. 2. По конструктивному решению:
- Ленточный: Выполняется в виде сплошной балки (ленты) под всеми несущими стенами.
- Плитный: Представляет собой сплошную монолитную плиту, объединяющую все сваи. Используется при сложных грунтах и высоких нагрузках.
- В виде отдельных балок: Применяется для связки свай под отдельно стоящие колонны или опоры.
Нормативная база (проверенные источники)
Проектирование и расчет ростверков регламентируются следующими документами:
- СП 50-102-2003: “Проектирование и устройство свайных фундаментов”. Основной документ, определяющий требования к проектированию.
- Пособие к СНиП 2.03.01-84: “Пособие по проектированию железобетонных ростверков свайных фундаментов”. Содержит детальные указания по расчету и конструированию.
- СНиП 52-01: Требования к бетонным и железобетонным конструкциям, на которые ссылаются при расчете ростверков.
Согласно этим нормам, для ростверков, как правило, применяют бетон класса В15 или В20, а армирование выполняют пространственными каркасами из арматуры класса А-III (А400).
Плюсы и минусы
Преимущества:
- Надежность на слабых грунтах: Позволяет строить на пучинистых, болотистых и других проблемных почвах.
- Устойчивость к подвижкам грунта: Обеспечивает высокую жесткость и сопротивление горизонтальным нагрузкам.
- Скорость монтажа: По сравнению с ленточным фундаментом, возводится быстрее.
Недостатки:
- Сложность расчета: Требует точного инженерного расчета нагрузок.
- Более высокая стоимость: По сравнению с незаглубленными ленточными фундаментами может быть дороже.
- Трудоемкость: Особенно для монолитных железобетонных конструкций, требующих устройства опалубки и армирования.
Где применяется
Ростверки - неотъемлемая часть свайных фундаментов, которые широко используются в самых разных областях:
- Индивидуальное строительство: Для возведения каркасных, деревянных, кирпичных и газобетонных домов на сложных грунтах.
- Промышленное и гражданское строительство: В фундаментах под колонны зданий и сооружений.
- Гидротехническое строительство: В причальных и портовых сооружениях.
- Мостостроение: В опорах мостов и эстакад.
-
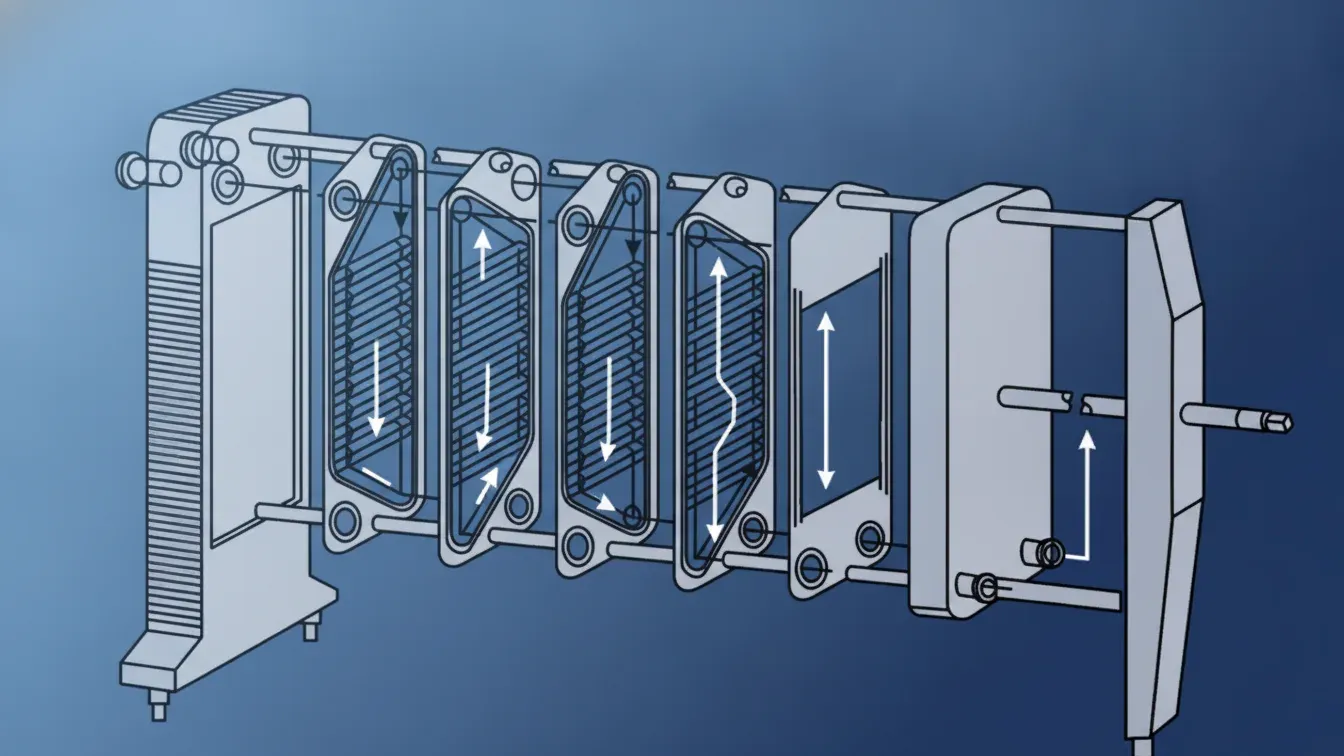 Как работает теплообменник пластинчатый
Как работает теплообменник пластинчатыйПластинчатый теплообменник - это устройство для эффективной передачи тепла между двумя средами (например, горячей водой из системы отопления и холодной водопроводной водой для ГВС) без их смешивания. Его ключевая особенность - высокая эффективность благодаря большой площади контакта и компактность.
Устройство и основной принцип работы
Основные элементы пластинчатого теплообменника:
- Пакет гофрированных пластин: Тонкие металлические листы (из стали, титана, меди) с выштампованными гофрами.
- Рама (станина): Неподвижная и подвижная плиты, стянутые шпильками, которые сжимают пакет пластин в единый блок.
- Уплотнительные прокладки: Резиновые прокладки, которые герметизируют каналы и направляют потоки жидкостей.
Принцип работы:
- Создание каналов: Пластины собираются в пакет так, что между ними образуются узкие щелевые каналы. Горячая и холодная среды движутся по соседним, герметично разделенным каналам.
- Противоток: Жидкости движутся навстречу друг другу (противотоком), что обеспечивает максимальную эффективность теплопередачи.
- Теплообмен: Тепло от горячей среды передается через тонкую стенку пластины холодной среде.
- Турбулизация: Гофрированная поверхность пластин создает турбулентные потоки, которые значительно повышают интенсивность теплообмена.
Нормативная база (проверенные источники)
Проектирование и изготовление пластинчатых теплообменников регламентируется рядом документов:
- ГОСТ 15518-87: Основной стандарт, распространяющийся на пластинчатые аппараты с поверхностью теплообмена от 1 до 800 м². Определяет типы, параметры и размеры.
- СП 41-101-95: Свод правил «Проектирование тепловых пунктов», который содержит методики теплового и гидравлического расчета.
- ГОСТ Р ИСО 15547-1-2009: Содержит требования к механическому расчету, выбору материалов и изготовлению для нефтяной, газовой и нефтехимической промышленности.
Где применяется
Благодаря своей эффективности, пластинчатые теплообменники широко используются:
- В системах отопления и горячего водоснабжения (ГВС) жилых и общественных зданий.
- В пищевой промышленности (например, для пастеризации молока).
- В химической, нефтехимической и энергетической отраслях.
-
 При какой температуре металл становится хрупким
При какой температуре металл становится хрупкимТемпература, при которой металл становится хрупким, не является фиксированной. Этот переход происходит в определенном температурном интервале, который называется порогом хладноломкости. Для каждого металла или сплава этот порог индивидуален и зависит от его химического состава, структуры и условий эксплуатации.
Что такое порог хладноломкости?
Это условный температурный интервал, в котором характер разрушения металла меняется с вязкого (пластичного) на хрупкий.
- Вязкое разрушение: происходит при высоких температурах, металл перед разрушением заметно деформируется.
- Хрупкое разрушение: происходит при низких температурах, разрушение наступает внезапно, без заметной пластической деформации.
За порог хладноломкости часто принимают температуру
T50- при которой в изломе образца содержится 50% вязкой и 50% хрупкой составляющей.От чего зависит температура перехода?
Температура перехода в хрупкое состояние может варьироваться в широчайших пределах: от нескольких сотен градусов выше нуля до температур, близких к абсолютному нулю. Это зависит от нескольких ключевых факторов:
1. Кристаллическая решетка металла:
- ОЦК-металлы (объемно-центрированная кубическая решетка): (α-железо, хром, вольфрам, молибден). Наиболее склонны к хладноломкости. Их температура перехода может быть как высокой (сотни °C для вольфрама), так и низкой (около 4 К (-269 °C) для очищенного тантала).
- ГЦК-металлы (гранецентрированная кубическая решетка): (алюминий, медь, никель, золото, платина). Сохраняют пластичность вплоть до очень низких температур и практически не склонны к хладноломкости.
- ГПУ-металлы (гексагональная плотноупакованная решетка): (титан, цирконий). Их пластичность ограничена уже при комнатной температуре.
2. Химический состав стали:
- Углерод ( C ): Повышает температуру порога хладноломкости. Каждые 0,1% углерода в стали повышают этот порог в среднем на 20°C. Например, при 0,4% C порог хладноломкости может быть около 0 °C, а при большей концентрации - достигать 20 °C.
- Фосфор (P): Является вредной примесью, сильно повышающей склонность к хладноломкости. Повышение содержания фосфора на 0,01% увеличивает порог хладноломкости на 25°C.
3. Прочие факторы:
- Толщина проката: С увеличением толщины металла порог хладноломкости смещается в область более высоких температур.
- Наличие концентраторов напряжений: Надрезы, царапины, трещины и другие дефекты повышают риск хрупкого разрушения, особенно при низких температурах.
Другие виды температурной хрупкости
Помимо хладноломкости, существуют и другие виды:
- Синеломкость: Временная потеря пластичности у углеродистых и низколегированных сталей, возникающая в диапазоне температур 200–400 °C.
- Высокотемпературная хрупкость: Охрупчивание, которое может происходить при длительной эксплуатации при температурах 550–850 °C или в интервале 700–1000 °C.
Практическое значение
Понимание порога хладноломкости критически важно в строительстве, машиностроении и при эксплуатации конструкций в холодном климате.
- Выбор материалов: Для арктических условий или зимнего строительства выбирают стали с низким порогом хладноломкости (специальные низкотемпературные или криогенные стали).
- Экспертиза разрушений: Анализ излома разрушившейся детали позволяет определить, произошло ли разрушение из-за хрупкости при низкой температуре.
-
 Фрикционное соединение металлоконструкций что это
Фрикционное соединение металлоконструкций что этоФрикционное соединение - это вид болтового соединения металлоконструкций, в котором передача внешней нагрузки между соединяемыми элементами происходит исключительно за счет сил трения, возникающих на их контактных поверхностях.
Это достигается путем сильного обжатия пакета соединяемых деталей высокопрочными болтами. Болты при этом работают только на растяжение, создавая необходимое усилие натяжения, а не на срез и смятие, как в обычных болтовых соединениях.
Как это работает: Ключевые элементы
- Высокопрочные болты: Используются специальные болты высокой прочности (например, классов 8.8, 10.9 или типов 110, 135). Их натяжение строго контролируется для обеспечения расчетного усилия обжатия.
- Подготовка поверхностей: Контактные плоскости соединяемых элементов проходят специальную обработку (пескоструйная, дробеметная, газопламенная, стальными щетками и т.д.) для достижения требуемого коэффициента трения.
- Передача усилия: Внешняя нагрузка, стремящаяся сдвинуть детали друг относительно друга, преодолевается не прочностью болта на срез, а именно силой трения между плотно сжатыми поверхностями.
Нормативная база (проверенные источники)
Существует ряд нормативных документов, регламентирующих проектирование, расчет и устройство фрикционных соединений:
- ГОСТ Р 71849-2024 (действует с 01.01.2025): Устанавливает метод определения коэффициента трения между контактными поверхностями для фрикционных соединений.
- СП 16.13330.2017: “Стальные конструкции”. Содержит общие правила расчета и проектирования, включая фрикционные соединения.
- ВСН 144-76 (утратил силу, но важен как исторический источник): Это была “Инструкция по проектированию соединений на высокопрочных болтах в стальных конструкциях мостов”, где четко давалось определение фрикционного соединения.
Преимущества фрикционных соединений
- Высокая надежность и вибростойкость: Отличное сопротивление динамическим и вибрационным нагрузкам.
- Высокий темп монтажа: Сборка выполняется быстрее, чем, например, клепка, и может производиться в любых погодных условиях.
- Меньшие требования к точности: Допускается меньшая точность сверловки отверстий по сравнению с обычными болтовыми соединениями, работающими на срез.
- Возможность усиления: Такие соединения удобны при реконструкции и усилении существующих конструкций.
Недостатки фрикционных соединений
- Высокая стоимость: Основной недостаток - высокая цена высокопрочных болтов и других метизов.
- Трудоемкость подготовки: Требуется тщательная и дорогостоящая подготовка контактных поверхностей (очистка, обработка) для обеспечения необходимого коэффициента трения.
- Контроль натяжения: Необходим строгий контроль усилия натяжения болтов, что требует специального оборудования и квалификации.
Сравнение с фрикционно-срезными соединениями
Важно не путать чисто фрикционные соединения с фрикционно-срезными. В последних внешняя нагрузка передается за счет совместной работы сил трения, а также сопротивления болтов срезу и стенок отверстий смятию. Это более распространенный, но менее надежный при вибрациях вариант.
Где применяются
Фрикционные соединения - это ответственный и высоконадежный вид соединения. Их применение оправдано в конструкциях, подверженных высоким динамическим и вибрационным нагрузкам:
- Мостостроение: Для соединения основных несущих элементов пролетных строений железнодорожных, автодорожных и пешеходных мостов.
- Промышленные сооружения: В конструкциях, работающих под действием крановых и других динамических нагрузок.
- Ответственные узлы: В соединениях, где сварка затруднена или нежелательна, а обычные болты не обеспечивают нужной надежности.
-
Кризис в металлообработке и металлоконструкциях в 2026 году
Здравствуйте, коллеги!
В последнее время отмечаю тревожные тенденции на рынке металлообработки и производства металлоконструкций. Несмотря на сохранение клиентской базы, наблюдаю следующее:
- общий спад деловой активности;
- участившиеся просчёты в планировании и реализации проектов;
- серьезные проблемы с оплатами со стороны заказчиков - задержки, неполные платежи, случаи отказа от обязательств.
А как обстоят дела у Вас? Наблюдаете ли вы проблемы или это только в общестроительном сегменте такой спад?
Какие меры предпринимаете для стабилизации фин положения?




© 2022 - 2026 InvestSteel, Inc. Все права защищены.